Video Overview: This video demonstrates different agent retrieval workflows—filter-based, SQL queries against a Postgres (Supabase) sales table, full-document context, and chunked vector retrieval. Through examples (sales by product/date, top revenue products, and a chronological breakdown of an “agent in 2 hours” video) it compares accuracy, speed, cost, and token usage. The presenter shows that full-context reads maintain order and accuracy but are heavier on tokens, while vector search is faster and cheaper yet may lose sequence fidelity.
– Filter example: agent uses product and date filters to return precise row-level answers (e.g., Bluetooth speakers sold on a specific date).
– SQL agent: runs aggregate queries against a Supabase/Postgres sales table to produce top revenue products and percentage breakdowns.
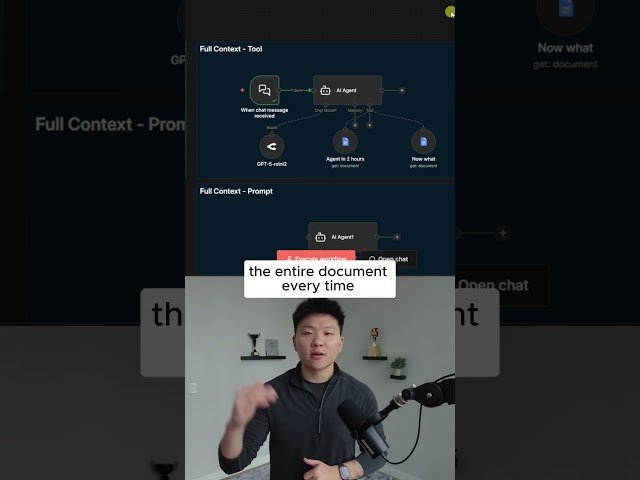
– Full-context method: the agent reads entire documents (not chunks) to produce ordered, accurate summaries; demonstrated token usage (4,000 of 400,000).
– Vector retrieval: chunked vectors in Supabase yield faster, cheaper responses but can lose ordering and some accuracy when reconstructing chronology.
Quotes:
Let the agent read the entire document every time rather than just looking for a specific chunk.
This only took 4,000 tokens out of GBT5 Mini’s 400,000 context window limit.
It’s faster and cheaper, but it’s not as accurate because it doesn’t understand order right now.
Statistics
| Upload date: | 2026-01-05 |
|---|---|
| Likes: | 1541 |
| Comments: | 11 |
| Statistics updated: | 2026-01-14 |
Specification: 4 Simple RAG Methods for Better AI Agents
|